
Gensim 모델은 왜 쓰는가? Gensim 모델은 언제 쓰는가?
토픽 모델링
Gensim은 LDA(Latent Dirichlet Allocation)와 같은 토픽 모델링 알고리즘을 제공한다.
이를 사용하여 대량의 문서에서 주제를 추출하고 문서가 다루는 주요 개념을 이해할 수 있다.
문서 유사성 분석: 문서 간 유사도를 계산하는 것은 문서 분류, 추천할때 쓸 수 있다.
Gensim의 Doc2Vec과 같은 모델은 이러한 작업에 적합하다.
차원 축소: 텍스트 데이터의 차원을 축소하여 계산 효율성을 높이고, 더 나은 시각화를 가능하게한다.
예를 들어, Gensim의 Word2Vec 모델을 사용하여 단어를 벡터 공간에 맵핑할 수 있습니다.
분산 컴퓨팅: Gensim은 분산 메모리 컴퓨팅을 지원하여 대용량 데이터를 더 빠르게 처리할 수 있다.
확장성 및 효율성: Gensim은 Python의 기본 자료구조를 효율적으로 사용하여 메모리를 절약하고,
대용량의 데이터셋도 처리할 수 있는 능력을 갖추고 있다.
Gensim은 이러한 기능들로 인해 많은 데이터 과학자들과 개발자들에게 선호되며,
텍스트 관련 머신러닝 프로젝트에 자주 사용된다.
이번에 작업한 Gensim 과제 - 국민청원 데이터를 사용했다.
불용어는 말그대로 분석할때 걸러야하는것들을 뜻함

토큰화 하고 토픽제시로 결과를만든다. (일부 캡쳐)

LDA 모델 생성 및 훈련을 한다.
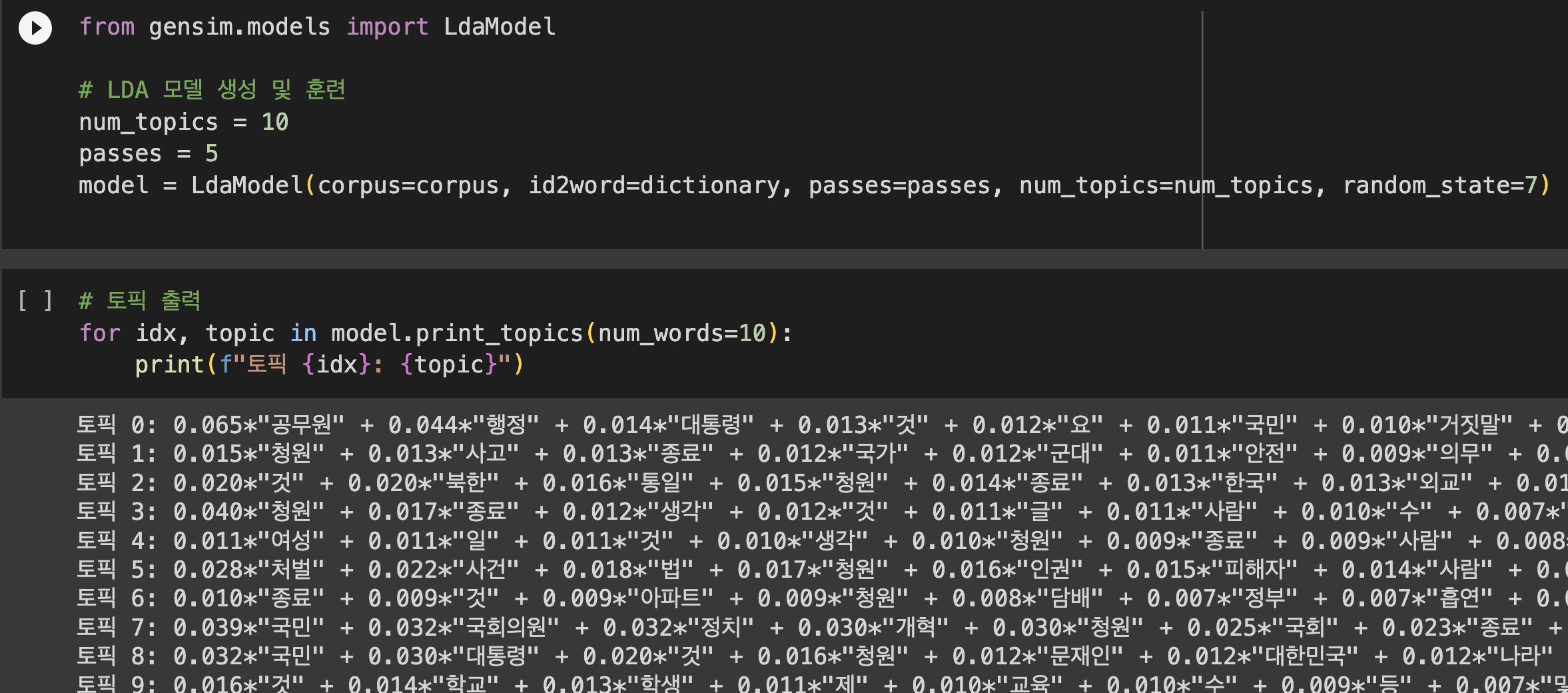
토픽 분포와 일관성 점수를 계산해본다.

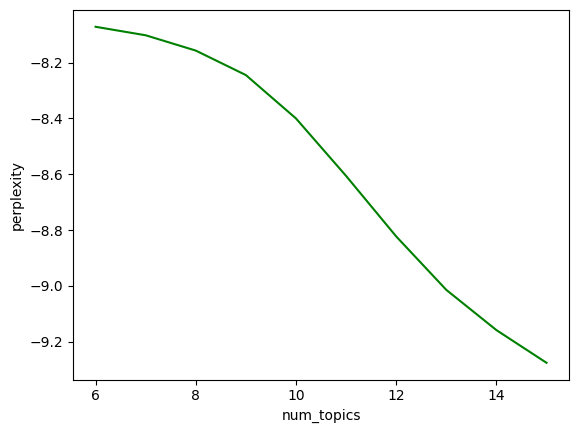
Perplexity(분기계수)와 코히어런스 시각화
*Perplexity는 헷갈리는 정도?로 이해하면 된다.
*Topic Coherence는 주제 일관성 정도로 이해하면 된다.

그럼 결과가 이렇게 나온다.

'데이터사이언스' 카테고리의 다른 글
| Doc2vec 실습하기 (0) | 2023.12.02 |
|---|---|
| Word2vec 실습해보기 (0) | 2023.12.02 |
| LDA란 무엇인가? (1) | 2023.11.27 |
| AI 융합의 시대 - LG전자 신정은 상무 특강 (1) | 2023.11.25 |
| 데이터 분석 EDA란 무엇인가? (feat.삽질을 덜 하려면) (2) | 2023.11.24 |




댓글