
LDA는 '잠재 디리클레 할당(Latent Dirichlet Allocation)'의 약자로, 문서 집합에서 주제를 모델링하기 위한 일종의 확률적 토픽 모델입니다. 이 방법은 문서가 여러 개의 주제로 구성될 수 있으며, 각 주제가 단어의 확률 분포를 가진다는 가정 하에 작동합니다. LDA의 목적은 각 문서에 대해 어떤 주제들이 얼마나 중요한지를 추정하고, 동시에 각 주제가 어떤 단어들로 구성되어 있는지를 파악하는 것입니다. 이러한 접근 방식은 텍스트 마이닝, 문서 분류, 정보 검색 등 다양한 분야에서 활용됩니다.
디리클레(Dirichlet)는 주로 통계학과 확률론에서 사용되는 개념으로, '디리클레 분포(Dirichlet distribution)'를 말합니다. 디리클레 분포는 여러 개의 비율이나 확률들이 어떻게 분포되어 있는지를 모델링할 때 사용되는 다변수 확률 분포입니다. 이 분포는 여러 개의 확률 변수가 모두 양수이면서 그 합이 1이 되는 조건을 만족할 때 주로 사용됩니다. 이러한 특징 때문에 디리클레 분포는 베이지안 통계학에서 사전 분포(prior distribution)로 자주 사용되며, LDA(잠재 디리클레 할당) 같은 토픽 모델링에서도 중요한 역할을 합니다. 디리클레 분포는 여러 구성 요소의 비율을 나타내는 문제에서 유용하게 적용됩니다.
LDA(잠재 디리클레 할당)를 사용하여 토픽을 알아내는 과정
모델 초기화: 먼저, 각 문서에 대해 임의로 주제를 할당한다.
이때 각 문서는 여러 주제를 포함할 수 있으며, 각 주제는 임의의 단어 분포를 가진다.
반복적인 업데이트: 모델은 각 단어에 대해 그 단어가 특정 주제에 속할 확률을 계산한다.
이 확률은 다음 두 가지 요소에 의해 결정됩니다:
- 해당 단어가 특정 주제에 얼마나 자주 등장하는가.
-해당 주제가 문서 전체에서 얼마나 중요한가.
-확률 계산: 모든 단어에 대해 이러한 계산을 수행하고, 각 단어의 주제 할당을 업데이트한다.
이 과정은 모델이 안정적인 상태에 도달할 때까지 반복된다.
결과 도출: 반복 과정이 끝나면, 각 문서에 대한 주제 분포와 각 주제에 속하는 단어의 분포가 결정됩니다. 이를 통해 우리는 각 문서가 어떤 주제들로 구성되어 있는지, 그리고 각 주제가 어떤 단어들로 이루어져 있는지 알 수 있습니다.
from sklearn.datasets import fetch_20newsgroups
# 선택할 카테고리 정의
categories = ['alt.atheism', 'talk.religion.misc', 'comp.graphics', 'sci.space',
'comp.sys.ibm.pc.hardware', 'sci.crypt']
# 훈련 데이터셋 불러오기
# 'train' 부분은 훈련 데이터셋을 의미하며, 'categories'는 선택한 카테고리를 필터링하는 데 사용됨
newsgroups_train = fetch_20newsgroups(subset='train', categories=categories)
# 훈련 세트 크기 및 선택된 카테고리 출력
print('#Train set size:', len(newsgroups_train.data))
print('#Selected categories:', newsgroups_train.target_names)
from sklearn.feature_extraction.text import CountVectorizer
# CountVectorizer를 사용하여 텍스트 데이터를 벡터 형태로 변환
# token_pattern: 토큰을 정의하는 패턴 (여기서는 길이가 3 이상인 단어들을 토큰으로 취급)
# stop_words: 불용어 설정 ('english'로 설정하여 영어 불용어 제거)
# max_features: 가장 빈도 높은 상위 2000개의 단어만을 사용
# min_df: 단어가 나타나야 하는 최소 문서 수 (여기서는 최소 5개 문서에 나타나는 단어)
# max_df: 단어가 나타날 수 있는 최대 문서 비율 (여기서는 모든 문서의 50%를 초과하는 단어 제외)
cv = CountVectorizer(token_pattern="[\w']{3,}", stop_words='english',
max_features=2000, min_df=5, max_df=0.5)
# 뉴스그룹 데이터를 CountVectorizer를 사용하여 변환
# 이 과정에서 텍스트 데이터는 각 단어의 빈도수를 나타내는 행렬로 변환됨
review_cv = cv.fit_transform(newsgroups_train.data)
from sklearn.decomposition import LatentDirichletAllocation
import numpy as np
np.set_printoptions(precision=3)
lda = LatentDirichletAllocation(n_components = 10, #추출할 topic의 수
max_iter=5,
topic_word_prior=0.1, doc_topic_prior=1.0,
learning_method='online',
n_jobs= -1, #사용 processor 수
random_state=0)
review_topics = lda.fit_transform(review_cv)
print('#shape of review_topics:', review_topics.shape)
print('#Sample of review_topics:', review_topics[0])
gross_topic_weights = np.mean(review_topics, axis=0)
print('#Sum of topic weights of documents:', gross_topic_weights)
print('#shape of topic word distribution:', lda.components_.shape)
def print_top_words(model, feature_names, n_top_words):
for topic_idx, topic in enumerate(model.components_):
print("Topic #%d: " % topic_idx, end='')
print(", ".join([feature_names[i] for i in topic.argsort()[:-n_top_words - 1:-1]]))
#print(", ".join([feature_names[i]+'('+str(topic[i])+')' for i in topic.argsort()[:-n_top_words - 1:-1]]))
# 위 slicing에서 맨 뒤 -1은 역순을 의미, 역순으로 했을 때 처음부터 n_top_words까지
print()
print_top_words(lda,cv.get_feature_names_out(), 10)

<혼잡도 계산하기>
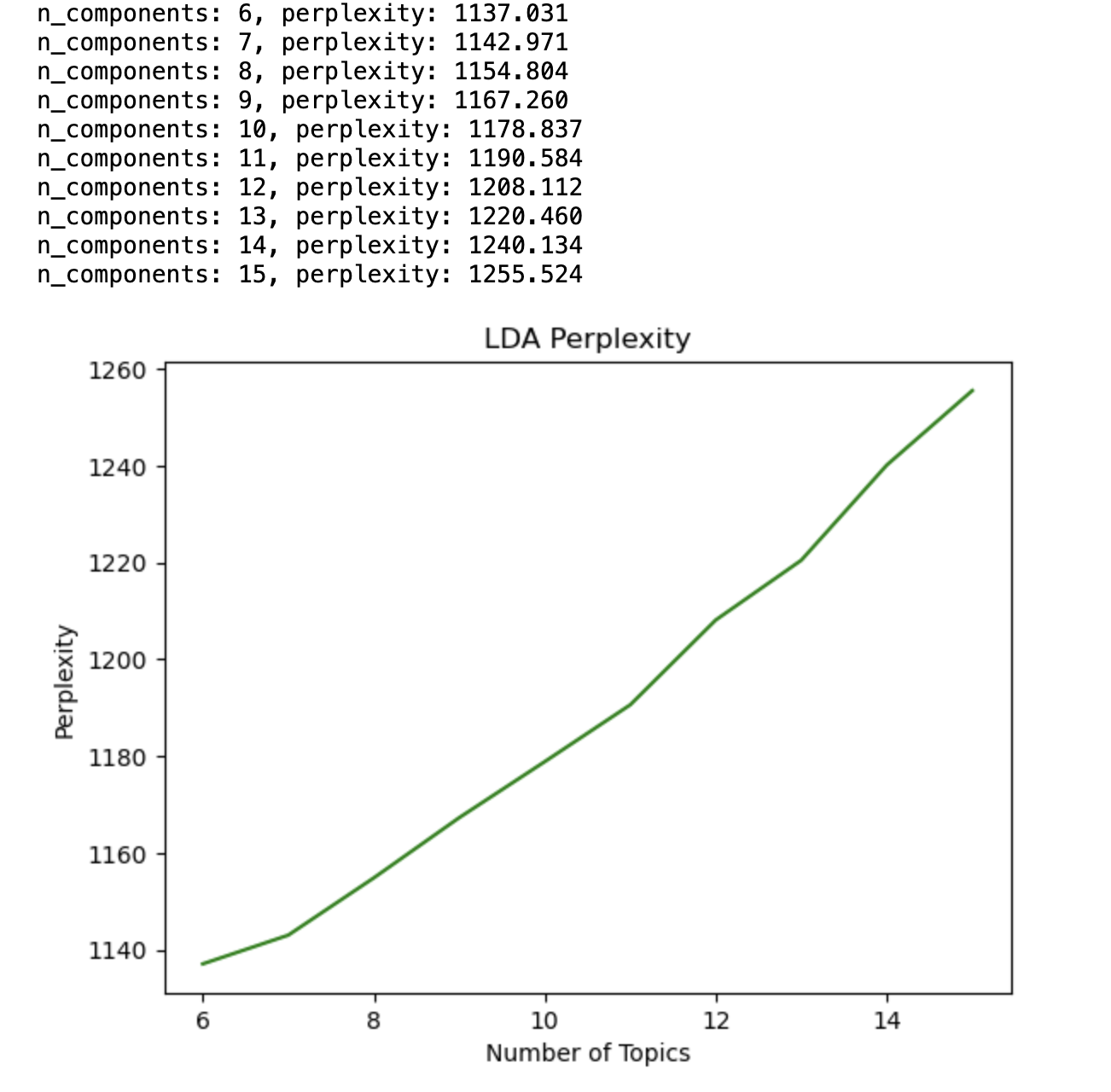
import matplotlib.pyplot as plt
%matplotlib inline
def show_perplexity(cv, start=10, end=30, max_iter=5, topic_word_prior= 0.1,
doc_topic_prior=1.0):
iter_num = []
per_value = []
for i in range(start, end + 1):
lda = LatentDirichletAllocation(n_components = i, max_iter=max_iter,
topic_word_prior= topic_word_prior,
doc_topic_prior=doc_topic_prior,
learning_method='batch', n_jobs= -1,
random_state=7)
lda.fit(cv)
iter_num.append(i)
pv = lda.perplexity(cv)
per_value.append(pv)
print(f'n_components: {i}, perplexity: {pv:0.3f}')
plt.plot(iter_num, per_value, 'g-')
plt.show()
return start + per_value.index(min(per_value))
print("n_components with minimum perplexity:",
show_perplexity(review_cv, start=6, end=15))
토픽 정하기
from sklearn.decomposition import LatentDirichletAllocation
# LDA 모델 설정 및 초기화
lda = LatentDirichletAllocation(n_components=8, # 추출할 주제의 수 지정
max_iter=20, # 최대 반복 횟수
topic_word_prior=0.1, # 주제 단어의 사전 확률 (기본값은 0.1)
doc_topic_prior=1.0, # 문서 주제의 사전 확률 (기본값은 1.0)
learning_method='batch', # 학습 방법 설정 ('batch' 또는 'online')
n_jobs=-1, # 사용할 프로세서 수 (-1은 모든 프로세서 사용)
random_state=7) # 난수 생성기 시드 값
# LDA 모델을 사용하여 리뷰 데이터 학습 및 주제 분포 추출
review_topics = lda.fit_transform(review_cv)
# 주제별 상위 단어 출력 함수
def print_top_words(model, feature_names, n_top_words):
for topic_idx, topic in enumerate(model.components_):
print("Topic #%d: " % topic_idx, end='')
print(", ".join([feature_names[i] for i in topic.argsort()[:-n_top_words - 1:-1]]))
print()
# 상위 단어 출력
print_top_words(lda, cv.get_feature_names_out(), 10)

'데이터사이언스' 카테고리의 다른 글
| Word2vec 실습해보기 (0) | 2023.12.02 |
|---|---|
| Gensim을 활용한 토픽 모델링 (0) | 2023.12.02 |
| AI 융합의 시대 - LG전자 신정은 상무 특강 (1) | 2023.11.25 |
| 데이터 분석 EDA란 무엇인가? (feat.삽질을 덜 하려면) (2) | 2023.11.24 |
| 책리뷰) 모두의 한국어 텍스트분석 with 파이썬 박조은, 송영숙 저 (0) | 2023.08.12 |




댓글